What is a SPOF?
A Single Point of Failure (SPOF) is a part of a system that, if it fails, will stop the entire system from working. This concept is crucial in designing systems that aim for high availability and reliability. In any system be it a business process, software application, or industrial setup a SPOF represents a critical risk. If there’s no backup or alternative path, the failure of this single component can lead to a complete system shutdown.
Real-World Examples of SPOF
1. Single Server Dependency
Imagine a company that relies on a single server to handle all its website traffic. If that server crashes, the website becomes inaccessible, leading to potential revenue loss and customer dissatisfaction.
2. Centralized Network Switch
Consider a network where all computers connect through one central switch. If this switch fails, communication between computers halts, disrupting operations.
3. Exclusive Supplier in Supply Chain
A business that depends on a single supplier for a critical component faces a SPOF. If the supplier can’t deliver, production stops, affecting the entire supply chain.
Common SPOFs in Businesses
Many businesses, especially growing ones, often have hidden single points of failure (SPOFs) that can cause major disruptions if overlooked. Recognizing these weak links early is key to building a more stable and resilient operation.
1. Single Internet Connection
If your office relies on one internet provider and that connection goes down, your entire team may lose access to cloud apps, emails, or customer systems. A backup connection or mobile hotspot is essential.
2. Single Server or Hosting Provider
Relying on one server or a single hosting provider without redundancy can shut down your website, application, or internal systems if that server crashes.
3. Centralized Power Supply
A single electrical source without a backup like a UPS (uninterruptible power supply) or generator can bring all operations to a halt during power outages.
4. Key Employees
When only one employee knows how a critical system works or holds admin access, they become a SPOF. If they’re unavailable, even routine tasks can become emergencies.
5. Critical Software Without Backup
Using one software platform without a backup or export option can be risky. If it crashes or loses data, your business may suffer huge delays or losses.
6. Single Data Storage Location
Storing all your data in one place whether it’s a hard drive or one cloud service without backup increases the risk of permanent data loss if that storage fails.
Why SPOFs are Problematic?
SPOFs are undesirable because they make systems vulnerable to complete failure. In IT systems, this can mean downtime, data loss, and security breaches. In business operations, it can lead to halted production, lost sales, and damaged reputation. Identifying and mitigating SPOFs is essential for resilience and continuity.
Identifying SPOFs in Your System
1. System Mapping
This means creating a visual plan or a diagram that shows how all the parts of your system work together. Imagine you’re drawing a map of a city’s roads to see how traffic flows. Similarly, in your system, you draw out all servers, networks, apps, and databases, and show how they connect and depend on each other. This helps you spot which parts are used most often or which parts don’t have a backup. For example, if only one server handles user logins and there’s no second one ready to take over, that server is a single point of failure. Tools like AlgoMaster and Taro help make this easier by automatically showing these connections and dependencies.
2. Dependency Analysis
Once you have your system map, the next step is to figure out how each part depends on others. Think of it like checking which machine in a factory depends on which part to keep working. If you notice that several services or systems all rely on one component (like one database or one API), and there’s no backup for that component, then it’s a SPOF. This means if that one thing fails, everything connected to it stops working too. AlgoMaster can help trace these dependencies and highlight risky ones.
3. Failure Impact Assessment
Here, you ask a simple but powerful question for each component: “What will break if this part fails?” If the answer is something like “the entire website goes down” or “all users lose access to data,” then you’ve identified a SPOF. This helps you decide which parts are critical and need a backup plan. It’s like checking which lightbulb, if it goes out, would leave the whole room dark. Sources like Informa TechTarget and AlgoMaster suggest doing this for every critical part of your system.
4. Chaos Testing
This is a practical way to test how your system behaves when something breaks on purpose. It’s like a fire drill but for your IT systems. You shut off a server, cut a network link, or block access to a database, and then watch what happens. The goal is to find weak spots or SPOFs before they cause real problems. Tools and methods from platforms like AlgoMaster help you simulate failures safely, so you can see how prepared your system really is.
Strategies to Mitigate SPOFs
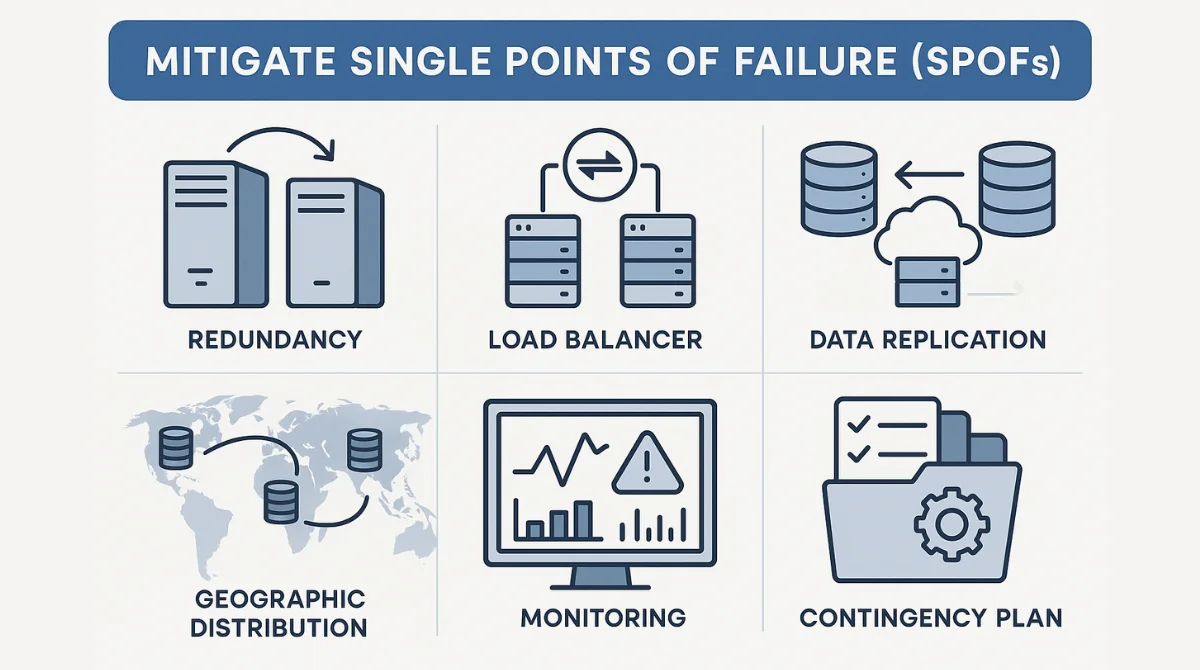
1. Implement Redundancy
This means having backup components ready to step in if something fails. Think of it like having a spare tire in your car. If one goes flat, you don’t get stranded you replace it and keep going. The same applies to computers, networks, software, and even people. For instance, if one server crashes, another one that’s already set up can automatically take over. Redundancy can be applied to employees too. If only one person knows how to fix a system, that’s a SPOF. But if two or more people are trained, the risk is lower. As Anomali recommends, redundancy is one of the best ways to reduce risk in any system.
2. Use Load Balancers
A load balancer is like a traffic cop that distributes incoming work (like user requests or data) across multiple servers. Instead of having all users connect to one server which creates a SPOF the load balancer sends each request to a different available server. If one server fails, the others keep working, and users probably won’t even notice anything went wrong. Tools like those from AlgoMaster and Anomali help companies set this up effectively.
3. Data Replication
This strategy means keeping multiple copies of your data in different places. So if one storage system fails due to a hard drive crash or a power outage you don’t lose important information. For example, if your customer database is stored only on one server and that server crashes, you’re in big trouble. But if it’s also saved in a cloud backup or a different physical location, you’re safe. Anomali and AlgoMaster both stress how important this is for business continuity.
4. Geographic Distribution
Instead of keeping all your systems or data in one place, you spread them across different cities, regions, or even countries. This way, if there’s a disaster like a flood, power outage, or even a local internet issue your services don’t go offline because systems in other places can keep running. Imagine if a power outage hits your main data center in United states but you’ve also got a backup running in United Kingdom. Your users won’t notice anything wrong. Companies like Aztech IT Solutions and AlgoMaster recommend this for protecting against large-scale disruptions.
5. Regular Monitoring and Maintenance
You don’t just wait for something to break you keep an eye on everything all the time. Monitoring tools check your systems 24/7 and alert you if something starts acting strange (like a server running slow or a network issue). Maintenance includes updating software, replacing old hardware, and cleaning up any technical issues before they cause a problem. This is like doing regular oil changes and checkups on your car cheaper and easier than fixing it after it breaks down.
6. Develop Contingency Plans
Sometimes, despite all your efforts, things still go wrong. That’s why it’s smart to have a plan ready. A contingency plan is a detailed guide that tells your team exactly what to do in case of a failure, like a server crash, data breach, or network outage. This includes who to contact, how to switch to backups, and how to recover data. Testing this plan regularly ensures it actually works in a real emergency. Protectallyourdata.com and Anomali both stress that this planning is just as important as the technical solutions.
Importance of Redundancy in System Design
Redundancy in system design means adding extra components that can take over if something fails, ensuring continuous operation. It’s key to preventing single points of failure and improving system reliability. This includes hardware redundancy like backup servers and network devices, and software redundancy using load balancers and failover systems. Data redundancy involves keeping multiple data copies through techniques like RAID or cloud backups to avoid data loss. Human redundancy is also vital cross-training staff and documenting processes ensures operations continue smoothly even if one person is unavailable. Proper planning and redundancy improve system resilience and reduce downtime significantly.
Strategic Redundancy Planning
Redundancy planning involves creating backups and failsafes. This section outlines how strategic redundancy planning can protect your organization from catastrophic failures.
1. Data Backup and Recovery
Regularly backing up data ensures that you can quickly recover in the event of a system failure. Cloud storage solutions offer scalable and reliable backup options.
2. Geographically Dispersed Data Centers
Utilizing data centers in different geographical locations ensures that others can take over, even if one center is compromised. This geographic redundancy is crucial for disaster recovery.
3. Failover Systems
Failover systems automatically switch to a backup system when the primary system fails. This method minimizes downtime by maintaining continuous operation.
Organizations can create a robust framework that significantly reduces the likelihood of catastrophic failures by systematically addressing hardware, software, data, and human redundancy. Implementing these strategies fosters a resilient IT infrastructure capable of withstanding unexpected disruptions and maintaining business continuity.
Planning for a Resilient Cyber Future
Planning for the future involves staying ahead of emerging threats. Incorporating advanced threat detection technologies into your cybersecurity strategy is crucial to combat cyber threats effectively.
1. Artificial Intelligence and Machine Learning
Artificial intelligence (AI) and machine learning (ML) are transforming the landscape of threat detection by identifying patterns and anomalies that traditional methods might miss. Implementing AI and ML solutions can provide real-time alerts and automated responses, significantly reducing the time it takes to mitigate threats.
2. Proactive Threat Hunting
Engage in proactive threat hunting to identify potential threats before they can cause harm. Continuously monitor your system for any unusual activities. Make sure your security policies are regularly updated to include the latest threats and technologies. Taking this proactive approach helps maintain a strong security posture.
3. Zero Trust Architecture
Zero Trust Architecture (ZTA) operates on the principle that no entity, inside or outside your network, should be trusted by default. This model enhances security by continuously verifying users, devices, and applications before granting access to resources. Implementing ZTA involves segmenting networks, continuously monitoring suspicious activities, and enforcing strict access controls, minimizing the risk of unauthorized access and potential breaches.
4. Educating and Empowering Employees
Human error remains one of the largest risks to cybersecurity. Regular training sessions and phishing simulations can empower employees to recognize and respond to cyber threats effectively. Establishing a clear protocol for reporting suspicious activities and rewarding proactive behavior can create a security-conscious organizational culture. Continuous education ensures that employees remain vigilant about the latest threat vectors.
5. Integrating Cybersecurity into Business Strategy
Cybersecurity should be a collaborative initiative rather than an integral part of the business strategy. Executive leadership must prioritize cybersecurity investments and align them with business objectives. This alignment ensures cybersecurity measures support the organization’s growth while protecting its assets.
6. The Role of Regulatory Compliance
Adherence to regulatory standards and compliance frameworks, such as GDPR, HIPAA, and PCI DSS, is crucial for maintaining cybersecurity resilience. Compliance helps avoid legal penalties and ensures robust security practices are in place. Regularly reviewing and updating policies to meet regulatory requirements is essential for protecting sensitive data and maintaining organizational integrity.
Conclusion
Understanding and addressing Single Points of Failure is vital for any organization aiming for resilience and reliability. By identifying potential SPOFs and implementing strategies like redundancy, failover systems, and continuous monitoring, businesses can safeguard against unexpected disruptions. Proactive planning, employee education, and integrating cybersecurity into business strategies further strengthen an organization’s defense against failures. In a world where system availability