In the world of machine learning, a training set is like a teacher’s lesson plan for a student. It’s the collection of examples that we give to a computer so it can learn to make decisions or predictions. Just as students learn better with clear examples, machines also need well-prepared data to understand patterns and make accurate predictions.
What Is a Training Set?
A training set is a group of data examples used to help a machine learning model learn how to make decisions. It includes input data along with the correct answers, called labels. For example, if you want a model to tell the difference between cats and dogs in pictures, you would collect many images of cats and dogs and label them correctly. The training set teaches the model by showing patterns in the data. Over time, the model starts to understand how a cat looks different from a dog. This process helps the model make smart guesses when it sees new, unlabeled images later on. A good training set helps the model become accurate and reliable.
Why Are Training Sets Important?
Training sets are very important in machine learning because they are what the model learns from. Just like a student needs good books and lessons to understand a subject, a machine learning model needs good training data to learn how to make decisions. If the training set has lots of examples and the information is correct and clear, the model can understand patterns better and make accurate predictions when it faces new data. But if the training data is messy, too small, or labeled incorrectly, the model might get confused and make wrong choices. So, the better the training set, the smarter and more useful the model will be.
Characteristics of Quality Training Sets
Creating a high-quality training set is essential for building machine learning models that are accurate, fair, and effective. Below are the key characteristics every good training set should have:
1. Accuracy
The data in the training set must be correct and reliable. If the information is wrong or misleading, the model will learn the wrong patterns, which leads to poor predictions.
2. Consistency
Consistent formatting and structure help the model learn faster and more accurately. For example, all entries should use the same units (e.g., all weights in kilograms) and label styles (e.g., all lowercase or all uppercase).
3. Completeness
A good training set should include enough data to represent the full range of possible inputs the model might face. Missing or incomplete data can leave gaps in the model’s understanding.
4. Diversity
The data should reflect real-world variety. This includes different types of users, conditions, environments, or situations. Diversity helps reduce bias and improves the model’s ability to generalize.
5. Proper Labeling
Each input (feature) must be correctly paired with the right output (label). In supervised learning, the model depends entirely on these labels to learn the correct answers, so any mistakes here can be damaging.
Components of a Training Set
When we talk about a training set in machine learning, we’re basically talking about the information we give to a computer so it can learn to make decisions or predictions. This training set has two main parts: features and labels.
1. Features (Inputs)
Features are like the clues or hints we give to the machine. These are the details or pieces of information that the computer will use to figure something out.
For example, imagine you want a computer to guess the price of a house. To help it do that, you give it some information about each house, like:
- How many bedrooms it has
- Where it’s located
- How big it is (square footage)
These pieces of information are called features. They are the “inputs” because we feed them into the machine learning model.
2. Labels (Outputs)
Labels are the correct answers we already know and include in the training data. In our housing example, the label is the actual price of the house.
So for every house in the training set, we have:
- The features (like bedrooms, location, size)
- The label (the real price)
By looking at lots of examples like this, the model tries to learn what kind of features lead to what kind of prices. It starts to notice patterns, like houses in certain locations are more expensive, or more bedrooms usually mean a higher price.
Putting It Together
When we give the model both the features and the labels, it can study the connection between them. This helps the model learn how to guess the price of a house it has never seen before, just by looking at the features.
In short:
- Features are the facts you know (like house details)
- Labels are the answers you want the model to learn (like house prices)
The better and more accurate your features and labels are, the smarter your model will become.
Preparing a Training Set
Before a machine learning model can learn, we have to give it good data. But just gathering data isn’t enough we need to prepare it carefully. Think of it like cooking: if your ingredients aren’t fresh or well-prepped, your dish won’t turn out well. Preparing a training set involves four key steps:
1. Data Collection
First, we need to collect the data we want to use. This means finding useful, real-world information from trustworthy sources.
For example, if you’re building a model to predict house prices, you might collect data from real estate websites, housing market reports, or databases.
Reliable data = better learning for the model.
2. Data Cleaning
Once we have the data, the next step is to clean it. Raw data often has problems like:
- Missing information (e.g., no price listed for a house)
- Duplicate entries (the same house listed more than once)
- Types or errors
Cleaning helps fix or remove these problems so the data is clear, consistent, and ready to use.
Clean data = fewer mistakes in training.
3. Data Labeling
Now that the data is clean, we need to label it especially if we’re using supervised learning, where the model learns from examples with correct answers.
For example:
- If the feature is a photo of a cat, the label might be “cat.”
- If the feature is house details, the label might be the actual house price.
4. Data Splitting
Finally, we split the data into different parts:
- Training Set: This is the main data the model learns from.
- Validation Set: This is used to tune the model’s settings during training.
- Test Set: This is used to check how well the model performs on data it has never seen before.
This split helps us know whether the model has actually learned something useful, or if it just memorized the training examples.
Splitting the data = testing the model’s real intelligence.
Training, Validation, and Test Sets
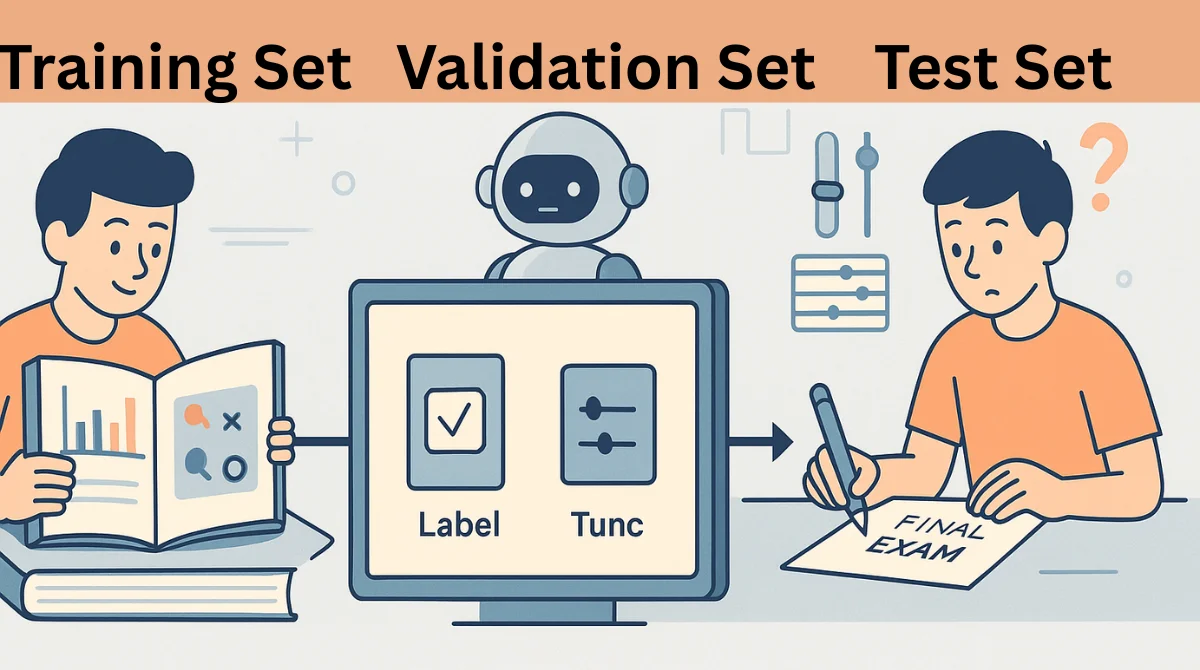
When training a machine learning model, we don’t just throw all the data into one bucket. Instead, we divide it into three parts to make sure the model learns properly and performs well on new data it hasn’t seen before. Think of it like preparing for a school exam:
1. Training Set
This is the data the model studies from just like a student studies from a textbook. It includes both the features (inputs) and the labels (correct answers), so the model can learn how things are connected.
2. Validation Set
After the model learns from the training set, we give it the validation set like a practice quiz. It helps us fine-tune the model’s “settings” or rules so that it doesn’t just memorize the training data. We can spot problems early, like overfitting, and make adjustments.
3. Test Set
Finally, the test set is like the final exam. It has new data the model hasn’t seen before. This shows us how well the model will perform in the real world.
Splitting the data this way helps the model become smart, not just good at memorizing.
Common Issues with Training Sets
While training models, some common problems can get in the way of building something useful:
1. Overfitting
Overfitting happens when the model learns the training data too well, including its mistakes or unusual patterns. Imagine a student memorizing every word in a textbook even the typos. They may do great on practice questions but struggle with new ones.
2. Underfitting
Underfitting is the opposite. It’s when the model is too simple or not trained enough to catch patterns in the data. It’s like a student who only skimmed the material and didn’t understand the key concepts. As a result, they can’t answer even the practice questions correctly.
3. Bias
Bias occurs when the training data doesn’t reflect the real world. For example, if a model that predicts job applicants’ success is trained only on data from one city or one age group, it might make unfair predictions about others. This can lead to wrong or even harmful results.
To build a good model, you need to avoid these issues by being careful about what data you use and how you use it.
Best Practices for Creating Training Sets
To create a training set that really helps your model learn the right way, follow these best practices:
1. Ensure Data Quality
Before using the data, clean it up. Fix errors, remove duplicates, and make sure everything is formatted correctly. Just like you wouldn’t want to study from a messy, outdated book, your model shouldn’t learn from bad data.
2. Use Representative Data
Your training data should reflect the variety of situations your model might face in the real world. For example, if you’re building a language translation model, include different accents, slang, and dialects.
3. Balance the Dataset
Make sure your training set isn’t too one-sided. For instance, if you’re training a model to detect spam emails and 95% of your data is non-spam, the model might not learn to recognize spam well. Give it enough examples of each case.
4. Regularly Update the Data
The world changes, and so should your training set. If you’re building a model for predicting shopping trends, last year’s data might already be outdated. Keep refreshing your data so your model stays relevant.
Conclusion
Training sets are the foundation of any successful machine learning model. They give the model the examples it needs to learn how to make accurate predictions. Without well-prepared training data, even the most advanced algorithms can fail. That’s why collecting reliable data, cleaning it, labeling it correctly, and keeping it up to date is so important. A high-quality training set helps the model understand real-world patterns, avoid mistakes, and stay relevant over time. It also ensures that the model performs well not just on the data it was trained with, but also on new, unseen situations. In short, good training data leads to smarter, more reliable, and more useful machine learning models.